|
|
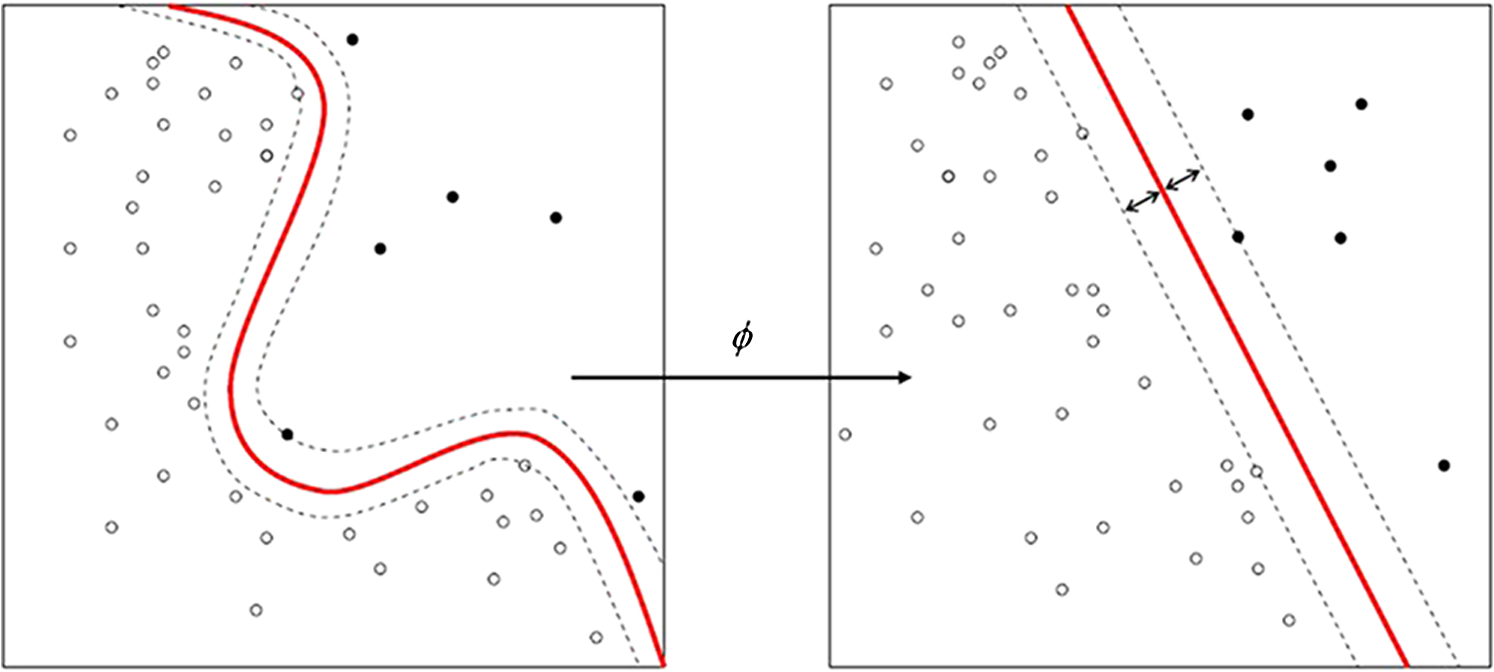
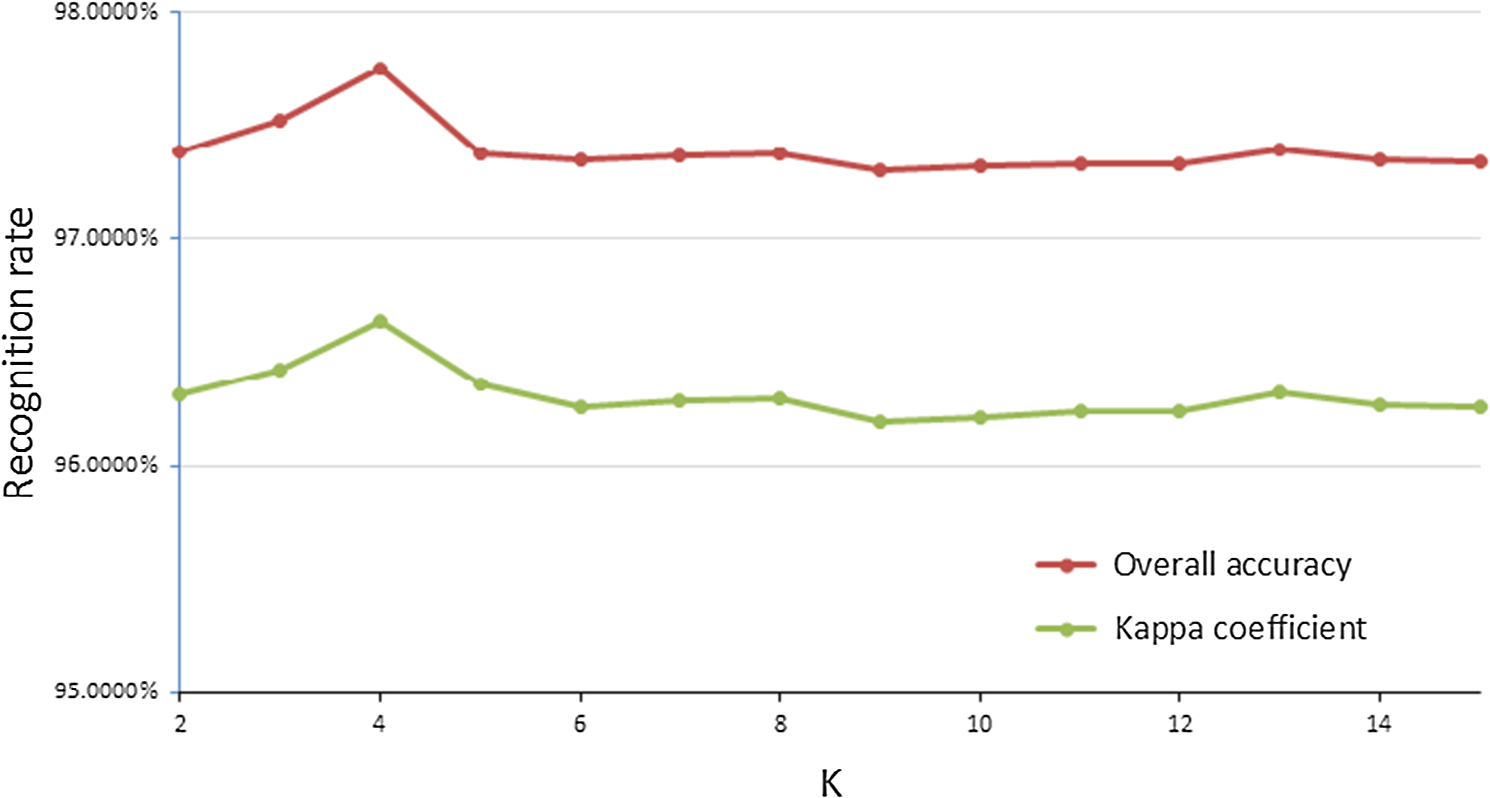
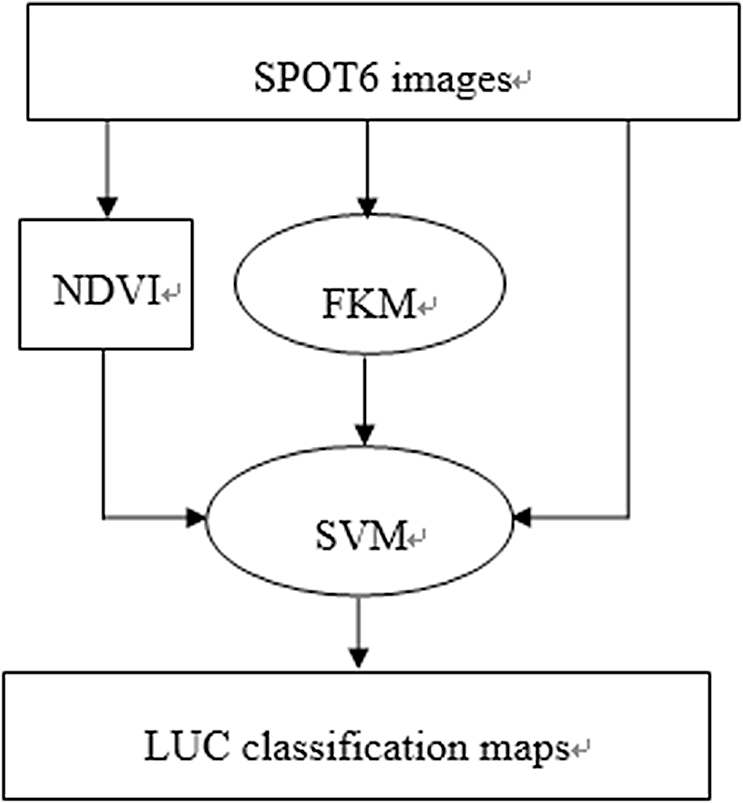
1.IntroductionLand use/cover (LUC) classification is a key research field in remote sensing, and plays an important role in climate change, biodiversity conservation, and people’s livelihoods. Accurate LUC maps derived from remotely sensed data have become the basis for analyzing many socio-ecological issues.1 LUC classification is nothing more than a convenient abstraction and may be improved by considering the other lines of evidence, such as surfaces that reflect the range of variability within and between the categories of a classification scheme.2 One basic issue to enhance the LUC classification is to choose an optimal classifier. A series of conventional classification methods have been well developed and long used for remote sensing applications, which are parallelepiped, minimum distance, and maximum likelihood (ML) models.3–5 Many other advanced classification techniques have also been introduced in the field of remote sensing classification, including artificial neural networks, machine-learning, decision trees, genetic algorithms, and support vector machines (SVM).6–10 Machine learning algorithms are widely used classification algorithms during the past decades and some assessments of their relative performance compared to other classifiers have been conducted in the Amazon region.11,12 SVMs (Refs. 13 and 14) have demonstrated their classification accuracies in several remote sensing applications.15 Specifically, SVMs have been shown to reach high accuracies in LUC mapping and outperform other algorithms.16–21 The success of such approaches is related to the intrinsic properties of the SVM classifier, which can handle ill-posed problems, and to the curse of dimensionality,22 which provides robust sparse solutions and delineates nonlinear decision boundaries between the classes. The SVM classifier has a significant advantage for LUC classification. It seeks to separate LUC classes by finding a plane in the multidimensional feature space that maximizes their separation, rather than by characterizing such classes with statistics. SVM classifiers do not need large training sets but just the training samples.23 Foody and Mathur24 suggested using small training sets composed of purposely selected mixed pixels containing the support vectors, since this approach does not compromise classification accuracies and may save considerable time. Another fundamental issue to enhance the LUC classification is the adequate selection of input variables, which may have the same impact as the selection of the classifiers as proposed by some authors. Watanachaturaporn et al.25 have used the multisource classification with SVM. Different textural measures are a potential source of ancillary data and their benefits for LUC classification have been highlighted in studies using different techniques and classifiers.26,27 Remote sensing images are large data, and clustering is the most important one in modern data mining technology, which is used in processing large data sets.28 Fuzzy classification is a well-established technique to classify multivariate units emerging in various vegetation, soil, and forestry studies.29,30 Fuzzy k-means (FKM) clustering algorithms have been used to overcome the problem of class overlap, but their usefulness may be reduced when data sets are large.29 In order to use both advantages of SVM and FKM clustering, we proposed a combination method to deal with LUC classifications in remote sensing images. The SVM classifier was used to generate a spectral-based classification map, whereas FKM clustering algorithm was adopted to provide an ensemble of segmentation map. The fusion of SVM and FKM algorithm aims at mitigating classes sort problems by completing the feature vector, and discovering the optimal nonlinear classification boundaries with SVM. The remainder of the paper is organized as follows: Section 2 introduces the classification algorithms and classification architectures to the reader. Section 3 presents the data sets as well as the experimental setup. Section 4 presents the results. Section 5 discusses the outcomes. Section 6 draws the conclusions of the paper. 2.LUC Classification AlgorithmsTo compare different classifiers, we used a parametric classifier (ML), nonparametric classifiers (SVM), and a hybrid classifier (unsupervised-supervised, fusion of SVM and FKM). We do not explain here how the ML and SVM algorithms work since detailed descriptions have already appeared in remote sensing and pattern recognition textbooks.31 2.1.SVM for LUC ClassificationAfter defining the data sets of remote sensing images which are used for classifying LUC, a robust classifier should be selected for the supervised classification step. SVM is chosen attributing to their intrinsic robustness to high-dimensional data sets and to ill-posed problems. The original SVM algorithm proposed by Vapnik in 1963 is a linear classifier. The basic idea of the SVM is to map multidimensional data into a higher-dimensional space, in which there is a hyperplane that can be used to linearly separate the original data, thereby maximizing the margin between different classes.14 Boser et al.32 suggested a way to create nonlinear classifiers by applying the kernel trick to maximum-margin hyperplane. The classifier aims at building a linear separation rule between examples induced by a mapping function in a higher-dimensional space on training samples. A linear separation in that space corresponds to a nonlinear separation in the original input space. An example is illustrated in Fig. 1. The core of such algorithm is given by the kernel trick: since mapped samples in the SVM formulation appear only in the form of dot products, these operations can be replaced by valid kernel functions returning directly to the inner product value in that space [dual formulation, Eq. (1)]. The solution is given by the hyperplane with maximal margin width, which guarantees the best generalization ability on previously unseen data. In the dual optimized formulation, one has to optimize32 where is a user-defined parameter controlling the trade-off between complexity and training error of the model, are the coefficients determining the solution of the optimization and (binary case) are the class labels associated to samples .When the solution to Eq. (2) is found, the label of an unknown sample is given by the sign of the decision function, i.e., its position with respect to the separating hyperplane Experiments are performed using a Gaussian radial basis function (RBF) kernel: , where is the user-defined bandwidth of the Gaussian function. The Gaussian RBF is usually used in many environmental applications to its interpretability.33 To solve multiclass problems, the one-against-all scheme is adopted.13 2.2.FKM Clustering for LUC SegmentationTo preliminarily classify LUC, a fuzzy segmentation is applied. The motivation for this choice is manifold. First, no fixed objects can be identified, as the concept of ground covers is inherently vague. Therefore, no clear, quantitative profiles exist. Second, some units between the boundaries are overlapped. In an FKM clustering, a record is retained by the degree to which any object belongs to all candidate classes. Specifically, for all objects being classified a real number in the range [0, 1] known as a membership value [denoted as ] is recorded for all classes being considered, where a value of indicates that there is no degree to which the object belongs to the class or set, , and indicates that it completely belongs to the set or class, , or could be considered as prototypical of the set. Values between and indicate the relative strength of the degree to which the object has properties that are typical of the set . Therefore, the outcome of FKM clustering is a record for every object being analyzed of the degree to which that object belongs to every single class being considered. FKM clustering algorithm is applied on the pixel values of all bands of remote sensing image. Depending upon the degree of fuzziness specified by the fuzziness parameter and the number of classes , this procedure yields a set of units, identified by the class with the highest membership value. In this study, considering data, , and will be done on the basis of the maximum partition coefficient [Eq. (3)] and the entropy parameter [Eq. (4)] is the membership value of pixel to class , .29,34 Both and depend on the number of classes . In fuzzy classification, the optimal number of classes and a fuzziness parameter were done by repeating the classification for a range of numbers of classes and parameters. In our two series of remote sensing images, we tried from 2 to 15, and got the highest accuracy when (Fig. 2). The fuzziness parameter was set to 2.0 according to various authors’ experience.292.3.Normalized Difference Vegetation IndexBesides the selection of image classifiers, the use of ancillary data is recognized as crucial for the performance of image classification. Ancillary data have been used successfully to improve image classification, especially by including topographic measures (elevation and slope), normalized difference vegetation index (NDVI), or texture measures in the classification process additionally to the spectral information for separating features with similar spectral properties.25,35–42 NDVI has become a standard remote sensing product for ecological applications,43 which has been widely applied for discriminating and interpreting mapped vegetation units.44,45 NDVI was calculated from where NIR is the near-infrared band and R is the red band.2.4.Fusion of SVM and FKM Classification ArchitecturesIn order to take advantage of the above described SVM and FKM algorithms, a proper method should be defined. The classification architectures are presented: (i) FKM clustering and (ii) SVM classification. The main scheme is shown in Fig. 3. FKM clustering algorithm is used to classify the original Systeme Probatoire d’Observation dela Tarre (SPOT) 6 image and produces clustering map. Simultaneously, NDVI layer is extracted from the original image. Both the clustering map and NDVI layer are added to the original image. Then, the SVM classifier is utilized to classify. Finally, an LUC classification map is obtained. 3.Material and Experiment Setup3.1.Study AreaQujing is a prefecture-level city in eastern Yunnan province of southwest China, which is similar to many central and eastern parts of the province. It is a part of the Yunnan-Guizhou Plateau. It is an important industrial city and is Yunnan’s second largest city by population, after Kunming. Its population is 5,855,055 according to the 2010 census, of which 659,925 reside in the residential area. Tempered by the low latitude and moderate elevation, Qujing has a mild subtropical highland climate, with short, mild, dry winters, and warm, rainy summers. 3.2.Data and PreprocessingA SPOT 6 image of the study zone was acquired on February 1, 2013. There were fewer clouds on the image. SPOT 6 satellite was launched on September 9, 2012. It has four multispectral bands: blue (450 to 525 nm), green (530 to 590 nm), red (625 to 695 nm), and near-infrared (760 to 890 nm). It also has a panchromatic (450 to 745 nm) band. Images of the panchromatic band can reach 1.5-m resolution and images of multispectral bands obtain 6-m resolution. After pansharpening using Bayesian data fusion, images of multispectral bands achieved a spatial resolution of 1.5 m. To reduce the computation of complexity and improve the classification accuracy, after topographic correction by digital elevation model, two sample images were clipped. The size of sample 1 images was [Fig. 4(a)], and the size of sample 2 was [Fig. 5(a)]. By visual inspection, a total of six LUC classes of interested regions had been highlighted by photointerpretation in both images. Finally, 460,024 pixels had been carefully labeled in sample 1 images [Fig. 4(b)] and 460,024 pixels had been labeled in sample 2 images [Fig. 5(b)]. The type of LUC was industrial, water, forest, rock, arable, and residential classes. Fig. 4Multispectral high resolution SPOT 6 image acquired over Qujing city, Yunnan province, China (sample 1). (a) RGB composition of image. (b) Ground survey of the six classes of interest identified: “industrial” (red), “water” (green), “forest” (yellow), “rock” (cyan), “arable” (magenta), and “residential” (blue). (c) ML LUC classification maps. (d) SVM LUC classification maps. (e) Fusion of SVM and FKM LUC classification maps. 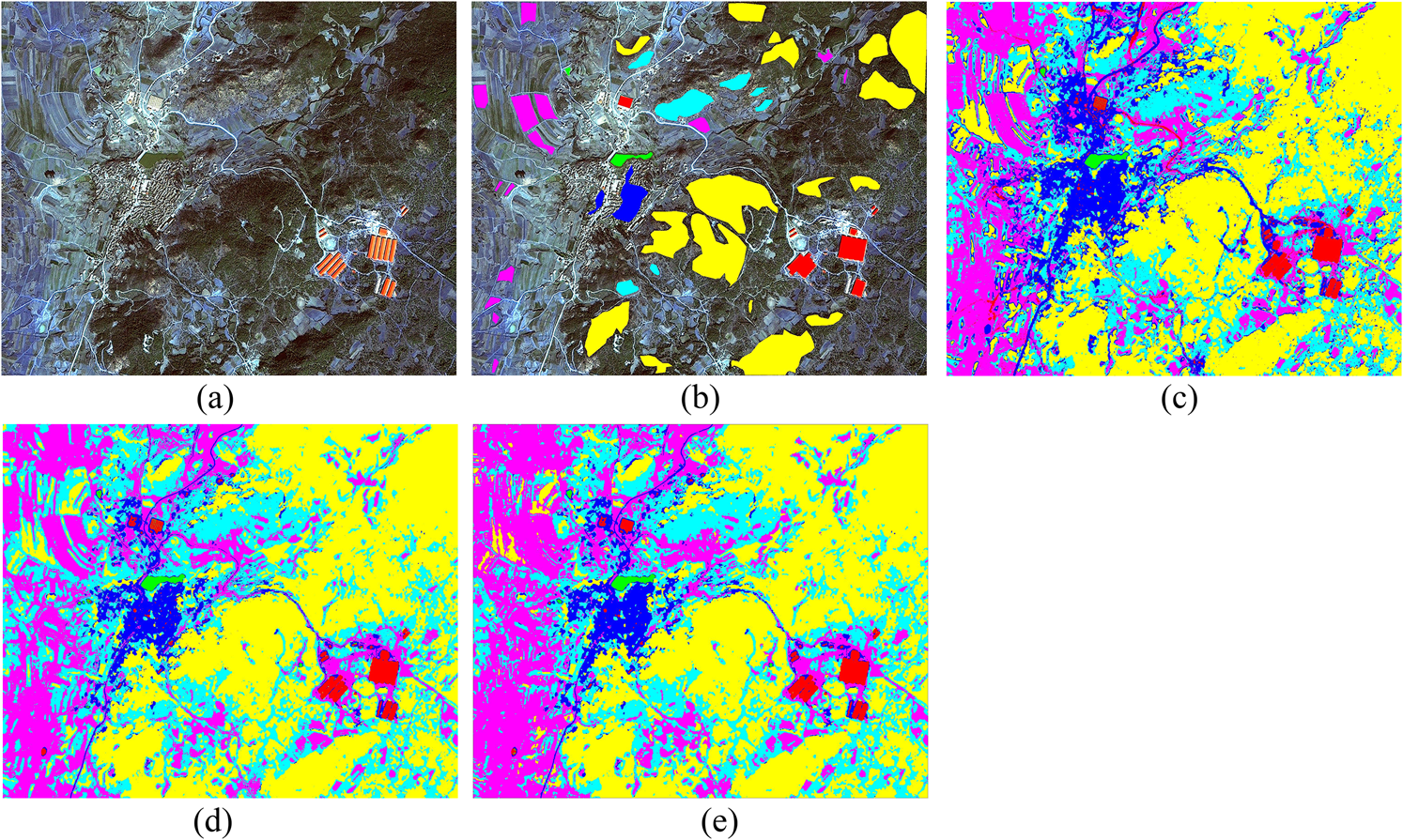 Fig. 5Multispectral high resolution SPOT 6 image acquired over Qujing city, Yunnan province, China (sample 2). (a) RGB composition of image. (b) Ground survey of the six classes of interest identified: “industrial” (red), “water” (green), “forest” (yellow), “rock” (cyan), “arable” (magenta), and “residential” (blue). (c) ML LUC classification maps. (d) SVM LUC classification maps. (e) Fusion of SVM and FKM LUC classification maps.  It can be easily found from the labeled images that in most cases data consists of small polygons [Figs. 4(b) and 5(b)]. Much care was taken to scatter training areas across each image to ensure that they were representative of the entire image, and to retrieve as many training samples for each LUC classes (Table 1) as needed to satisfy the previously suggested criteria for establishing an appropriate minimum sample size.31 The Jeffries–Matusita transformed divergence index was used to assess the separability of samples data. We confirmed that separability was rather high for industrial, water, and forest, but much lower for the rock class. These pixels were all used for supervise classifiers training and validation. Table 1Size of LUC samples (#pixels) collected from each classification.
3.3.Experimental SetupTo compare various kinds of algorithms, the ML, SVM, fusion of FKM, and SVM classifier were used. All algorithms were implemented using ENVI+IDL 4.8 in Windows 7. In this paper, combining of SVM and FKM algorithm was mainly divided into two steps. First, the NDVI layer was calculated from the red and near-infrared bands of SPOT 6 image using Eq. (5); an FKM clustering algorithm was used to produce segmentation map from all four bands of the image. After that, the segmentation map and NDVI layer were stacked to the original SPOT 6 image. Second, the SVM classifier was finally set up to calculate and produce the LUC classification map. After producing the LUC classification map, a majority filter was applied to all classifications to eliminate the salt and pepper noise in order to improve the accuracy. Reference data retrieval for accuracy assessment was based on a stratified random sample selection, with sample units taken at a minimum distance of 2 km to avoid the potential effects of spatial autocorrelation. The data were ground-truthed by expert-knowledge from the images themselves. For overall and each class’s obtained accuracy assessment, a confusion matrix (also known as error matrix) was generated, which is the most standard method for remote sensing classification accuracy assessment.46 4.ResultsThe classification maps produced by ML, SVM, fusion of FKM, and SVM classifiers are presented in Figs. 4 and 5. In Fig. 4, all classification approaches identified forest class as the LUC class occupying more than half of the total area of the zone, followed by arable class. All methods identified water class as the LUC class with the smallest area. On the contrary, the water class accounted for the largest proportion in Fig. 5. Confusion matrices of each classification algorithm were produced to analyze classes’ separation performance. In the sample 1 image, each classifier with overall accuracy (OA) assessed at 95.4156%, 96.5497%, and 97.7760% of ML, SVM, and fusion of SVM and FKM, respectively (Table 2). The OA of ML, SVM, and fusion of SVM and FKM classifiers was 92.5530%, 96.8847%, and 97.7552% (Table 3). From both the tables, the ML classification approach created the lowest producer’s and user’s accuracies for the individual classes. Table 2Sample 1 LUC classification accuracy (%) of three classifiers.
Table 3Sample 2 LUC classification accuracy (%) of three classifiers.
The sample 1 confusion matrix of fusion of FKM and SVM classification algorithm is shown in Table 4. Although the fusion of SVM and FKM classification attained highly accurate overall results, it was markedly less effective in recognizing rock and residential. About 0.43% of industrial was mistaken as residential while 1.98% of residential was wrong labeled as industrial class. Table 4Confusion matrixes representing best overall of classification using fusion of SVM and FKM in sample 1.
The sample 2 confusion matrix of fusion of FKM and SVM classification algorithm is also shown in Table 5. The classifier was less effective in recognizing residential to industrial or rock. About 13.31% of industrial was mistaken as residential and 14.40% of rock was wrong labeled as residential class. Table 5Confusion matrixes representing best overall of classification using fusion of SVM and FKM in sample 2.
5.DiscussionsML classification map held the most details, while SVM classification map got the least particulars. It is due to SVM algorithm eventually translating into a convex optimization problem, which can guarantee the global optimal. However, ML classifier is focused on resolving the local problem and ensuring the local optimal. Tables 2 and 3 demonstrate the SVM classifier is more effective than ML classifier in LUC classification. It is also coincided with that SVM classifier is better than ML classifier in LUC classification which was referred from many references.47,48 Fusion of FKM and SVM classifier got the highest OA among three classifiers. The highest overall classification accuracy generated by fusion of FKM and SVM in this study suggests that our approach is useful in conducting land LUC classification. The result was seriously influenced by the training samples because there were some shadows existing in residential and industrial training samples. The proposed method was less effective in the separation of rock and arable classes. It may be due to the date of the SPOT 6 image. The image was captured in winter. Few crops were growing on the farm in that season, so the huge area of bare soil on the farm land led to difficulty in distinguishing arable class and rock class. Because some trees or grasses grow in rock areas; and similarly, some forest areas without vegetation and bare rock turned out, the size of ground objects relative to the spatial resolution of a sensor is directly related to image variance.49 Some errors were made between forest and rock classes. About 1.16% of rock class pixels was mistaken as forest class. About 2.06% forest and 4.86% rock were wrongly classified as residential class (Table 4), only 0.24% of forest wrongly taken as rock and 0.94% of rock mistaken as forest, which may also be caused by the residential training sample. The reasons for the big mistake distinguishing residential, industrial, and rock are as follows. First, the residential houses were smaller than the other LUC classes on the SPOT 6 image, and the residential class sample contained some trees, grasses, and naked ground. Second, there were similar buildings between the residential and industrial zones. It can also be found that factories were built on hills and residential houses were placed near to pool from classification map, which resulted from local land use policy. Local administrators regulated to build industrial parks on the barren slopes, construct town on mountains, and develop agriculture around dams. The essence of land utilization was that the urban industrial went to the top of mountains while bottoms were exploited as farmland. This policy had brought great significance to urbanization of Yunnan province. More than 20 million hectares of mountain land were sorted out for industrial or urban use till 2012.50 6.ConclusionThis paper has proposed a fusion of SVM and FKM classification methods. The method can improve efficiency when dealing with remote sensing images. In this paper, the usefulness of the NDVI layer and FKM segmentation map has been demonstrated to be able to improve SVM classification in SPOT 6 images. Experiments on the SPOT 6 image classification problem showed good results, and encourage future and deep research in the field of LUC classification. To our knowledge, this is first time SVM and FKM algorithms have been combined to classify LUC. Foremost work is to focus on higher resolution images and combine more information. Our findings are promising because accurate mapping of LUC is highly challenging over heterogeneous areas, particularly in subtropical regions, and yet this task is important to conservation initiatives, climate change mitigation strategies, and the design of management plans and rural development policies. Our classification approach presents the advantage of being easy to implement, as both the calculation of NDVI and the presence of SVM classifier are readily available in remote sensing software and cost-effective, as SVM classifiers may use smaller training data sets without compromising classification accuracy. Importantly, the highly accurate results obtained by this approach suggest its great potential for LUC mapping in subtropical areas. We will assess in other areas in the near future. AcknowledgmentsThis research was supported by the Special Public Interest Research and Industry Fund of Forestry (No. 200904003-1) and the Project of Forestry Science and Technology Research (No. 2012-07). The research was also partly supported by Zhejiang A&F University Foundation (2044010012) and Zhejiang Province Major Science and Technology project (2011C12047). The authors would like to thank Yonggang Chen for sharing his great expertise on remote sensing images and GIS. The authors thank the editors and the anonymous reviewers for their useful input. ReferencesP.-G. Jaimeet al.,
“Enhanced land use/cover classification of heterogeneous tropical landscapes using support vector machines and textural homogeneity,”
Int. J. Appl. Earth Obs. Geoinf., 23 372
–383
(2013). http://dx.doi.org/10.1016/j.jag.2012.10.007 0303-2434 Google Scholar
C. Linet al.,
“Beyond classifications: combining continuous and discrete approaches to better understand land-cover change within the lower Mekong River region,”
Appl. Geogr., 39 26
–45
(2013). http://dx.doi.org/10.1016/j.apgeog.2012.11.021 0143-6228 Google Scholar
S. Couturieret al.,
“A model-based performance test for forest classifiers on remote-sensing imagery,”
For. Ecol. Manage., 257
(1), 23
–27
(2009). http://dx.doi.org/10.1016/j.foreco.2008.08.017 FECMDW 0378-1127 Google Scholar
O. HagnerH. Reese,
“A method for calibrated maximum likelihood classification of forest types,”
Remote Sens. Environ., 110
(4), 438
–444
(2007). http://dx.doi.org/10.1016/j.rse.2006.08.017 RSEEA7 0034-4257 Google Scholar
J. Jensen, Introductory Digital Image Processing: A Remote Sensing Perspective, 3rd ed.Prentice-Hall, Englewood Cliffs, New Jersey
(2005). Google Scholar
H. Baganet al.,
“Land cover classification from MODIS EVI times-series data using SOM neural network,”
Int. J. Remote Sens., 26
(22), 4999
–5012
(2005). http://dx.doi.org/10.1080/01431160500206650 IJSEDK 0143-1161 Google Scholar
P. F. Fisher,
“Remote sensing of land cover classes as type 2 fuzzy sets,”
Remote Sens. Environ., 114
(2), 309
–321
(2010). http://dx.doi.org/10.1016/j.rse.2009.09.004 RSEEA7 0034-4257 Google Scholar
U. Kumar,
“Comparative evaluation of the algorithms for land cover mapping using hyperspectral data,”
International Institute for Geo-information Science and Earth Observation Enschede, Netherlands, Indian Institute of Remote Sensing, National Remote Sensing Agency (NRSA), Department of Space, GOVT. of India, Dehradun, India,
(2006). Google Scholar
B. SchölkopfA. Smola, Learning with Kernels, MIT Press, Cambridge, Massachusetts
(2002). Google Scholar
J. SouthworthC. Gibbes,
“Digital remote sensing within the field of land change science: past, present and future directions,”
Geogr. Compass, 4
(12), 1695
–1712
(2010). http://dx.doi.org/10.1111/geco.2010.4.issue-12 1749-8198 Google Scholar
J. M. B. CarreirasJ. M. C. PereiraY. E. Shimabukuro,
“Land-cover mapping in the Brazilian Amazon using SPOT-4 vegetation data and machine learning classification methods,”
Photogramm. Eng. Remote Sens., 72
(8), 897
–910
(2006). http://dx.doi.org/10.14358/PERS.72.8.897 PGMEA9 0099-1112 Google Scholar
D. S. Luet al.,
“Comparison of land-cover classification methods in the Brazilian Amazon Basin,”
Photogramm. Eng. Remote Sens., 70
(6), 723
–731
(2004). http://dx.doi.org/10.14358/PERS.70.6.723 PGMEA9 0099-1112 Google Scholar
J. Shawe-TaylorN. Cristianini, Kernel Methods for Pattern Analysis, Cambridge University Press, Cambridge, UK
(2004). Google Scholar
V. Vapnik, Statistical Learning Theory, Wiley, New York
(1998). Google Scholar
G. Camps-VallsL. Bruzzone, Kernel Methods for Remote Sensing Data Analysis, Wiley, New York
(2009). Google Scholar
G. M. FoodyA. Mathur,
“A relative evaluation of multiclass image classification by support vector machines,”
IEEE Trans. Geosci. Remote Sens., 42
(6), 1335
–1343
(2004). http://dx.doi.org/10.1109/TGRS.2004.827257 IGRSD2 0196-2892 Google Scholar
C. HuangL. S. DavisJ. R. G. Townshend,
“An assessment of support vector machines for land cover classification,”
Int. J. Remote Sens., 23
(4), 725
–749
(2002). http://dx.doi.org/10.1080/01431160110040323 IJSEDK 0143-1161 Google Scholar
T. KavzogluI. Colkesen,
“A kernel functions analysis for support vector machines for land cover classification,”
Int. J. Appl. Earth Obs. Geoinfor., 11
(5), 352
–359
(2009). http://dx.doi.org/10.1016/j.jag.2009.06.002 0303-2434 Google Scholar
G. MountrakisJ. ImC. Ogole,
“Support vector machines in remote sensing: a review,”
ISPRS J. Photogramm. Remote Sens., 66
(3), 247
–259
(2011). http://dx.doi.org/10.1016/j.isprsjprs.2010.11.001 IRSEE9 0924-2716 Google Scholar
M. PalP. M. Mather,
“Support vector machines for classification in remote sensing,”
Int. J. Remote Sens., 26
(5), 1007
–1011
(2005). http://dx.doi.org/10.1080/01431160512331314083 IJSEDK 0143-1161 Google Scholar
B. W. SzusterQ. ChenM. Borger,
“A comparison of classification techniques to support land cover and land use analysis in tropical coastal zones,”
Appl. Geogr., 31
(2), 525
–532
(2011). http://dx.doi.org/10.1016/j.apgeog.2010.11.007 0143-6228 Google Scholar
G. Hughes,
“On the mean accuracy of statistical pattern recognizers,”
IEEE Trans. Inf. Theory, 14
(1), 55
–63
(1968). http://dx.doi.org/10.1109/TIT.1968.1054102 IETTAW 0018-9448 Google Scholar
G. M. FoodyA. Mathur,
“Toward intelligent training of supervised image classifications: directing training data acquisition for SVM classification,”
Remote Sens. Environ., 93
(1–2), 107
–117
(2004). http://dx.doi.org/10.1016/j.rse.2004.06.017 RSEEA7 0034-4257 Google Scholar
G. M. FoodyA. Mathur,
“The use of small training sets containing mixed pixels for accurate hard image classification: training on mixed spectral responses for classification by a SVM,”
Remote Sens. Environ., 103
(2), 179
–189
(2006). http://dx.doi.org/10.1016/j.rse.2006.04.001 RSEEA7 0034-4257 Google Scholar
P. WatanachaturapornM. K. AroraP. K. Varshney,
“Multisource classification using support vector machines: an empirical comparison with decision tree and neural network classifiers,”
Photogramm. Eng. Remote Sens., 74
(2), 239
–246
(2008). http://dx.doi.org/10.14358/PERS.74.2.239 PGMEA9 0099-1112 Google Scholar
S. Berberogluet al.,
“The integration of spectral and textural information using neural networks for land cover mapping in the Mediterranean,”
Comput. Geosci., 26
(4), 385
–396
(2000). http://dx.doi.org/10.1016/S0098-3004(99)00119-3 CGEODT 0098-3004 Google Scholar
M. Chica-OlmoF. Abarca-Hernández,
“Computing geostatistical image texture for remotely sensed data classification,”
Comput. Geosci., 26
(4), 373
–383
(2000). http://dx.doi.org/10.1016/S0098-3004(99)00118-1 CGEODT 0098-3004 Google Scholar
J. P. Bigus, Data Mining with Neural Networks, McGraw-Hill, New York
(1996). Google Scholar
P. A. BurroughP. F. M. van GaansR. A. Mac Millan,
“High-resolution landform classification using fuzzy-k-means,”
Fuzzy Sets Syst., 113
(1), 37
–52
(2000). http://dx.doi.org/10.1016/S0165-0114(99)00011-1 FSSYD8 0165-0114 Google Scholar
P. A. Burroughet al.,
“Fuzzy k-means classification of topo-climatic data as an aid to forest mapping in the Greater Yellowstone area, USA,”
Landscape Ecol., 16
(6), 523
–546
(2001). http://dx.doi.org/10.1023/A:1013167712622 LAECEH 0921-2973 Google Scholar
B. TsoP. M. Mather, Classification Methods for Remotely Sensed Data, CRC Press, Taylor & Francis Group, Boca Raton, Florida
(2009). Google Scholar
B. E. BoserI. M. GuyonV. N. Vapnik,
“A training algorithm for optimal margin classifiers,”
in Proc. of the 5th Annual ACM Workshop on Computational Learning Theory (COLT),
(1992). Google Scholar
M. KanevskiA. PozdnoukhovV. Timonin, Machine Learning for Spatial Environmental Data, EPFL Press, Lausanne
(2010). Google Scholar
P. A. BurroughR. A. McDonnell, Principles of Geographical Information Systems, Oxford University Press, Oxford, UK
(1998). Google Scholar
S. Berberogluet al.,
“Texture classification of Mediterranean land cover,”
Int. J. Appl. Earth Obs. Geoinf., 9
(3), 322
–334
(2007). http://dx.doi.org/10.1016/j.jag.2006.11.004 0303-2434 Google Scholar
G. A. Carpenteret al.,
“A neural network method for efficient vegetation mapping,”
Remote Sens. Environ., 70
(3), 326
–338
(1999). http://dx.doi.org/10.1016/S0034-4257(99)00051-6 RSEEA7 0034-4257 Google Scholar
F. GiannettiL. MontanarellaR. Salandin,
“Integrated use of satellite images, DEMs, soil and substrate data in studying mountainous lands,”
Int. J. Appl. Earth Obs. Geoinf., 3
(1), 25
–29
(2001). http://dx.doi.org/10.1016/S0303-2434(01)85018-2 0303-2434 Google Scholar
M. A. Islamet al.,
“Semi-automated methods for mapping wetlands using Landsat ETM plus and SRTM data,”
Int. J. Remote Sens., 29
(24), 7077
–7106
(2008). http://dx.doi.org/10.1080/01431160802235878 IJSEDK 0143-1161 Google Scholar
S. M. JoyR. M. ReichR. T. Reynolds,
“A non-parametric, supervised classification of vegetation types on the Kaibab National Forest using decision trees,”
Int. J. Remote Sens., 24
(9), 1835
–1852
(2003). http://dx.doi.org/10.1080/01431160210154948 IJSEDK 0143-1161 Google Scholar
J. KozakC. EstreguilK. Ostapowicz,
“European forest cover mapping with high resolution satellite data: the Carpathians case study,”
Int. J. Appl. Earth Obs. Geoinf., 10
(1), 44
–55
(2008). http://dx.doi.org/10.1016/j.jag.2007.04.003 0303-2434 Google Scholar
D. LuQ. Weng,
“A survey of image classification methods and techniques for improving classification performance,”
Int. J. Remote Sens., 28
(5), 823
–870
(2007). http://dx.doi.org/10.1080/01431160600746456 IJSEDK 0143-1161 Google Scholar
H. Saadatet al.,
“Landform classification from a digital elevation model and satellite imagery,”
Geomorphology, 100
(3–4), 453
–464
(2008). http://dx.doi.org/10.1016/j.geomorph.2008.01.011 GMPHAA 0169-555X Google Scholar
N. Pettorelliet al.,
“Using the satellite-derived NDVI to assess ecological responses to environmental change,”
Trends Ecol. Evol., 20 503
–510
(2005). http://dx.doi.org/10.1016/j.tree.2005.05.011 TREEEQ 0169-5347 Google Scholar
S. K. Honget al.,
“Ecotope mapping for landscape ecological assessment of habitat and ecosystem,”
Ecol. Res., 19
(1), 131
–139
(2004). http://dx.doi.org/10.1111/j.1440-1703.2003.00603.x ECRSEX 1440-1703 Google Scholar
A. F. RahmanJ. A. Gamon,
“Detecting biophysical properties of a semi-arid grassland and distinguishing burned from unburned areas with hyperspectral reflectance,”
J. Arid Environ., 58
(4), 597
–610
(2004). http://dx.doi.org/10.1016/j.jaridenv.2003.12.005 JAENDR 0140-1963 Google Scholar
R. G. CongaltonK. Green, Assessing the Accuracy of Remotely Sensed Data—Principles and Practices, CRC Press, Taylor & Francis Group, Boca Raton, Florida
(2009). Google Scholar
L.-q. ChenL. WangL.-s. Yuan,
“Analysis of urban landscape pattern change in Yanzhou city based on TM/ETM+ images,”
Proc. Earth Planet. Sci., 1
(1), 1191
–1197
(2009). http://dx.doi.org/10.1016/j.proeps.2009.09.183 PEPSAI 1878-5220 Google Scholar
K. S. Prashantet al.,
“Selection of classification techniques for land use/land cover change investigation,”
Adv. Space Res., 50
(9), 1250
–1265
(2012). http://dx.doi.org/10.1016/j.asr.2012.06.032 ASRSDW 0273-1177 Google Scholar
C. E. WoodcookA. Strahler,
“The factor of scale in remote sensing,”
Remote Sens. Environ., 21
(3), 311
–332
(1987). http://dx.doi.org/10.1016/0034-4257(87)90015-0 RSEEA7 0034-4257 Google Scholar
H. Zu,
“Changing land use patterns and developing industrial and towns on mountains,”
(2012) http://yndaily.yunnan.cn/html/2012-10/09/content_631152.htm?div=-1 Google Scholar
BiographyTao He is a PhD student at Beijing Forestry University, majoring in forest management. His research interests are GIS system applications, monitoring, and evaluation of forest resources. He is also a teacher at Zhejiang A&F University. Yujun Sun is a professor at Beijing Forestry University, majoring in the field of forest management. He is also working as a forest management researcher and senior consultant for sustainable forest and natural resource management projects. He also serves as a member of the board, International Boreal Forest Research Association; council member, Ecological Society of China; president, ESC-Eco-tourism; standing council member and deputy secretary general, CSF-Forest Management; standing council member, CSF-Forest Park. Ji-De Xu is an engineering professor and a director general of Department of Forest Resources Management in State Forestry Administration (SFA). He is in charge of forest resources management, forestland management, forest resources investigation etc. His focus is on the 8th National Forest Inventory. Xue-Jun Wang is a senior engineer, mainly engaged in forest resource monitoring and GIS remote sensing application. Chang-Ru Hu works for the Department of Forest Resources Management, State Forestry Administration (SFA). Her working responsibilities include forest resources management, forest conservation, forest resources management and supervision, forest land conservation, examination and approval of forest land requisition and occupation etc. She has a master’s degree from Bradford University in the United Kingdom. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||