
|
|
1.IntroductionRemote sensing is an effective technology to extract and map spatially explicit information of land use and cover at different scales.1,2 Forest cover maps are one of the products made using remotely sensed data and are essential for forest management, habitat monitoring, and biodiversity analysis.3–6 General-purpose land cover maps developed at national and global scales usually describe forest information at a coarse level. For example, the National Land Cover Database (NLCD)7 for the United States contains three forest types: deciduous, evergreen, and mixed forests, a level-II classification defined by the United State Geological Survey (USGS).8 For the purposes of intensive forest management, habitat characterization, and forest health monitoring, it is essential to obtain more detailed forest information than the USGS (or Anderson) level-II classification can provide.9–11 The major challenge in land use or forest classification is to increase classification detail with satisfactory accuracy.12–14 This is because forest classification can theoretically be made at any level but classification accuracy decreases with increasing classification detail. Fine-level forest cover maps with low classification accuracy are no better than coarse-level forest cover maps with high classification accuracy though different forest management activities may require different forest cover maps. A three-forest-class (or Anderson’s level-II) land cover map works well for national-scale forest assessment, but is insufficient for complex forest management at the state level, such as in Indiana where 95% of forests are deciduous.15 In this region, distinct deciduous hardwood forest types exist, requiring differing silvicultural regimes for management and maintenance.10,16 However, detailed classification of hardwood forests is difficult due to the similarities in spectral reflectance, canopy structure, and spatial mixture of hardwood tree species.17 There is a clear need for a quality forest cover map in Indiana to assess the habitat availability for bat species that are at risk from white-nose syndrome.18 For example, the Indiana bat (Myotis sodalis) is listed as an endangered species by the U.S. Fish and Wildlife Service as well as the International Union for Conservation of Nature.19 Populations of Indiana bats have declined from 1960 to 200120 and are under considerable threat of increased declines due to white-nose syndrome.21 During the summer, Indiana bats mainly use hardwood and hardwood-pine forests22 and a quality forest cover map can assist in modeling current and future bat habitat.23 There are several existing forest cover maps that contain more than three forest types at national or state scales. The Forest Cover Types map produced by the National Atlas of the United States24 provides an alternative resource for obtaining a forest cover map in Indiana. This dataset was created based on advanced very high resolution radiometer and Landsat Thematic Mapper (TM) imagery acquired in 1991 and includes 25 types of forests with a 1-km spatial resolution. The classifications of hardwood forests, however, do not separate maple (Acer sp.) from mixed hardwood tree species groups despite the fact that maple is one of the most dominant tree genera in Indiana. Furthermore, there is no accuracy assessment information associated with the metadata. The Indiana Gap Analysis Project has also produced a land cover map.25 The development of this land cover map focused upon habitat attributes but did not consider subclasses of hardwood forests. The overall accuracy of this map was just 70.98%. However, for the assessment of land use and land cover mapping, the USGS proposed a recommendation of minimum accuracy of 85%.8 For application in landscape quantification, a classification accuracy of is necessary.13 Although there is no specific accuracy requirement for the purpose of forest managements and habitat delineation, our objective was to develop a forest cover map with 85% or better classification accuracy. Existing land cover maps were not satisfactory in terms of classification details and accuracy; therefore, it was necessary to develop a more accurate and more detailed forest cover map to meet the needs of various spatial analyses, such as wildlife habitat simulations. The algorithms of image data classification to derive a forest cover map generally include supervised and unsupervised approaches.26 Supervised classifications require training a dataset to predefine the statistical parameters (such as maximum likelihood) or nonparametric statistical learning functions (such as neural network and support vector machine).27,28 Unsupervised classifications (such as ISODATA and K-means clustering) generate spectral clusters based on the statistical information of the remote sensing imagery.29,30 Supervised and unsupervised classifications each have their own strengths: the former involves more human input than the latter, whereas the latter is more repeatable than the former. Strictly speaking, both approaches require human experience and neither is absolutely repeatable in practice. It is ideal for a classification algorithm to have minimal human input while maintaining a high level of accuracy and repeatability.30–33 Lang et al.30 demonstrated a data-aided unsupervised classification (DUC) method that interfaced with sample data for labeling spectral classes into information classes. This automated classification approach is superior to the traditional supervised and unsupervised classification methods in terms of ease of use, classification accuracy, and repeatability. However, the use of DUC becomes impractical if there are insufficient ground sample data. Our access to thousands of geo-referenced plots of forest inventory from Indiana State Forests (ISF) provides us with an excellent opportunity to classify forest types with the DUC method. This study represents the first application of DUC to reveal insight about the usefulness of this automated approach in practice. 2.Study Area and Data ProcessingThis study focused on ISF and the 8-km surrounding areas (37°57′N to 40°54′N, 85°28′ W to 87°38′W). Eight-kilometer surrounding areas were implemented because they encompass the majority of Indiana bat movement from roost sites to foraging areas.34,35 A total of 13 state forests with a total area of were included in the study area (Fig. 1). Located in the central hardwood forest region, the forests in the study area are dominated by hardwood species, such as oak (Quercus sp.), hickory (Carya sp.), maple, and tulip poplar (Liridodendron tulipifera). Fig. 1The extents of Indiana State Forests (ISF) and the 8-km surrounding areas across Indiana. The area between the lines is covered by the Landsat TM path 21 constituting of the study area. The Landsat TM data were placed as the background with the RGB combination of bands 4, 3, and 2.  We downloaded cloud-free Landsat 5 TM data of paths 21 and 22, and rows 32, 33, and 34, acquired in April 2006, September 2008, and October 2010 from the USGS Earth Explorer data website (Table 1).36 There were limited stand-replacing commercial harvests within the study area between 2006 and 2010. A comparison between NLCD 2006 and NLCD 2011 within the study area indicated that only 0.114% of forestland had changed on ISF and the 8-km surrounding areas. Therefore, the overall forest canopy structure remained generally intact during this period. These satellite image data capture spectral characteristics of tree species in spring and fall seasons. The use of different seasons of remotely sensed data has proven useful for improving classification accuracy for mapping tree species in temperate deciduous woodlands.37 In the spring, the deciduous trees have varying levels of greenness due to differences in leaf-growing stages. In the fall, discrimination among deciduous species is possible due to differing colors and amounts of leaves. Therefore, the combination of the two-season datasets increases the ability to distinguish hardwood forest types in Indiana. Mosaics were made from images acquired on the same date and were all clipped with the boundary of our study area. Spring and fall TM image datasets were combined into a single dataset, resulting in two datasets covering 97 and 3% of the area by path 21 and path 22, respectively (Fig. 1). The data-aided classification method (discussed below) was applied to the classification of the path 21 image mosaic. The path 22 image mosaic was classified with a traditional unsupervised classification method due to insufficient plot data available for this small area.26 Table 1Landsat 5 Thematic Mapper data used in this study.
NLCD 2006 was used as a base map, which helped separate forest from nonforested areas (Fig. 2). This ensured the consistency between the newly developed land cover map and NLCD 2006 data for the nonforest categories. We clipped the image mosaics with forest polygons and derived image datasets that contained only forest pixels (Fig. 2). Fig. 2A flow chart of applying the two-stage, data-aided unsupervised classification method in forest cover mapping for ISFs and the 8-km surrounding areas.  Continuous Forest Inventory (CFI) plot data were collected on ISF by Indiana Department of Natural Resources (IDNR) between 2006 and 2010 (Fig. 3).38 The sampling intensity was one plot for approximately every 40 acres. Each plot is in a circular shape with a radius of 7.3 m. Stand type was recorded and trees with a diameter at breast height of 5 in. and larger were measured on each plot. In this study, they were used as reference data () for image classification (Table 2). We grouped all the CFI plots into five forest types: conifer forest, conifer-hardwood forest, maple forest, mixed hardwood forest, and oak-hickory forest based upon the surveyors’ forest type classification. The coniferous forest type included all the conifer-dominated plots. If the plot contained both hardwood and coniferous tree species, it was grouped into conifer-hardwood forest type. Maple forest plots were those dominated by maple trees. Plots would belong to oak-hickory forest type if they were dominated by oak and co-dominated by hickory. Mixed hardwood forest plots were those dominated with hardwood tree species other than maple, oak, or hickory. We collected data from an additional 321 plots for accuracy assessment39,40 based on the CFI technique above, and 248 of these additional plots were located within ISF area. The 8-km surrounding areas were much greater than ISF in area, but contained only a small portion of reference plots due to difficult accessibility to private forestland. Table 2The distribution of Continuous Forest Inventory plots among forest types in Indiana State Forest.
3.Classification MethodsBand selection is required to improve efficiency and reduce redundancy. Different bands of Landsat 5 TM data have different features for forest mapping.41,42 Band 1 has the ability to distinguish deciduous from coniferous vegetation. Band 2 is useful for assessing plant vigor. Band 3 is sensitive to vegetation slopes. Band 4 is related to forest biomass content. Bands 5, 6, and 7 reflect the moisture content of soil and vegetation.43 We performed band-by-band visual examinations to eliminate bands with obvious noise due to high scattered energy and excluded band 6 because of its large pixel size. Only one band would be kept if some bands provide similar information for forest mapping to reduce redundancy. The TM data analysis and classification were performed in Erdas Imagine 2010 (Ref. 44) and MATLAB® 2010a. The classification procedure included two stages (Fig. 2).
Quantity, allocation, and total disagreements, which were developed by Pontius and Millones,46 were calculated to qualify the classification results statistically in each stage. Quantity disagreement is defined as the amount of difference in the proportions of the categories between the resultant map and the reference data. Allocation disagreement is the difference in spatial allocation of the categories between the resultant map and the reference data. Total disagreement is the sum of quantity and allocation disagreements.46 McNemar’s test was used to test the significant difference between the resultant matrices in stages 1 and 2.47,48 The Z score was calculated with the following equation: where was the number of samples that were misclassified by the first stage classification but were correctly classified by the second stage classification, and was the number of samples that were correctly classified by the first stage classification but were misclassified by the second classification. We assumed the results from the two stages were statistically significant () if the value was .A complete land cover dataset was then produced by overlaying this forest cover map with the water layer derived with the original TM imagery and the existing NLCD 2006. The newly derived forest cover dataset is referred to as a five-forest-class (FFC) map, containing conifer forest, conifer-hardwood forest, maple forest, mixed hardwood forest, and oak-hickory forest. 4.ResultsIn the band selection procession, we selected nine bands from the Landsat 5 TM data for forest cover mapping, including bands 2, 3, 4, and 5 from the 2006 TM data, bands 4 and 5 from the 2008 TM data, and bands 4, 5, and 7 from the 2010 TM data. Bands 1 of all Landsat data were excluded because of the high scattered energy. Bands 6 were all eliminated due to the large pixel size and because the information they provided was not critical for forest mapping. One out of three of bands 2, 3, and 7 were kept to reduce the redundancy. All bands 4 and 5 were included because they are sensitive to the seasonal changes of the spectral reflectance of the forest species. To separate oak-hickory forest from other forest types in stage 1, we started with 100 spectral clusters using unsupervised classification and increased the number of the clusters by a 50-cluster interval.26 By adjusting the number of spectral clusters, the highest classification accuracy was reached when the number of spectral clusters was 200. For the classification of non-oak-hickory forest types, the classification accuracy reached the highest when the number of spectral clusters was 100. In this step, there would be individual spectral cluster/clusters that had no overlap with any CFI plot if there were too many spectral clusters. The FFC map within ISF was created at this stage [Fig. 4(a)]. In the second stage, 200 spectral clusters were classified to create an FFC map within ISF and the 8-km surrounding areas [Fig. 4(b)]. The accuracy was expressed with spatial agreement of forest types within shared ISF area between two forest cover maps from both stages. Fig. 4The ISF forest cover map (a), the forest cover map of the ISF and the 8-km surrounding areas (b), and the National Land Cover Database (NLCD) 2006 (c). 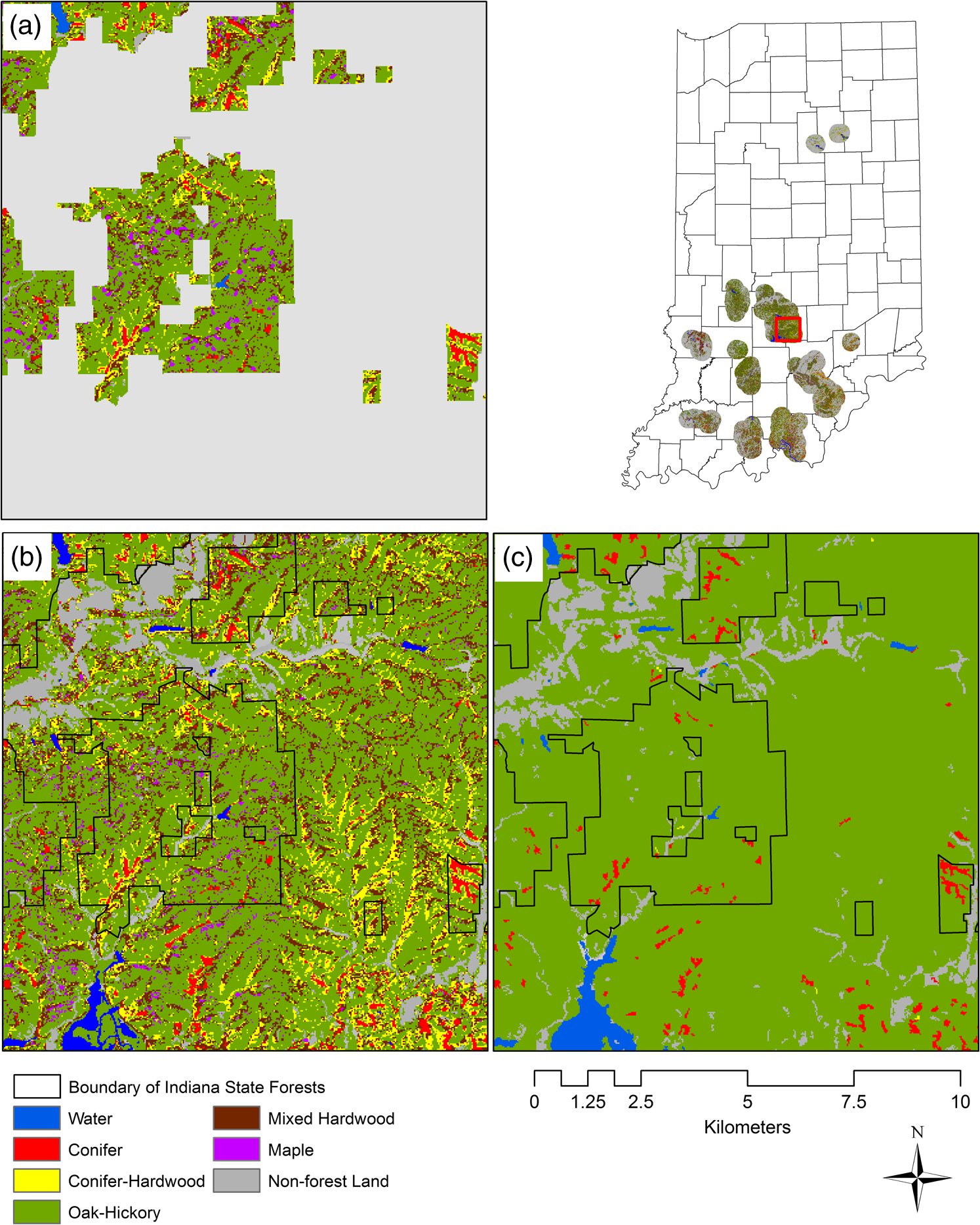 The FFC map resulting from the first stage of the classifications reached an overall accuracy of 74.2% (Table 3). The quantity and allocation disagreements were 0.052 and 0.206. The total disagreement was 0.258.46 The oak-hickory forest type had the highest accuracy on the average of user’s and producer’s accuracies, followed by conifer, conifer-hardwood, maple, and mixed hardwood forests. The classification accuracies of conifer-hardwood, maple, and mixed hardwood forests were lower than desirable. The second stage of the classifications increased the overall accuracy to 81.9% (Table 4), better than the 78% overall accuracy of NLCD 2006 level II classification [Fig. 4(c)].49 The total disagreement was 0.176 with a quantity disagreement of 0.028 and allocation disagreement of 0.148. Again, the oak-hickory forest type had the highest accuracy; conifer and maple forest types also had satisfactory accuracies. The mixed hardwood forest type had a rather low producer’s accuracy though its user’s accuracy was relatively high. McNemar’s test was applied to compare the results from the first and second stages of the classification. There were 73 plot samples that were used in the second stage of the classification but were not used in the first stage of the classification because they were located in the 8-km surrounding areas of ISF. As McNemar’s test requires the same quantity of samples from these two matrices, these 73 samples were not used in the McNemar’s test, among which, 7 samples were misclassified in the second stage of the classification. The value of the McNemar’s test was 2.98, which was . Therefore, the difference of the results from the two classification stages was statistically significant at a 96% confidence level, which means that the result in the second stage of classification was significantly improved. Table 3An error matrix of classification for forests within Indiana State Forest following the stage one classification.
Note: UA, user’s accuracy; PA, producer’s accuracy; OA, overall accuracy. Table 4An error matrix of classification for forests in Indiana State Forest and the 8-km surrounding areas following the stage two classification.
Note: UA, user’s accuracy; PA, producer’s accuracy; OA, overall accuracy. The FFC map shows the dominant compositions of oak-hickory and mixed hardwood forests in forest landscape, comprising 81% of the forested landscape in areas within ISF [Fig. 5(a)]. This result was consistent with forest composition data reported by IDNR (2008),10 which were obtained from field observations. Maple forest type in the FFC map constitutes 7% of ISF area, equivalent to the sum of 4% for maple and 3% for bottomland hardwoods (IDNR 2008) [Fig. 5(b)]. The combined area of conifer and conifer-hardwood mixed forests in the FFC map was slightly more than the pine forest area reported by IDNR (2008). The proportion of conifer-hardwood forest in the FFC map was reasonable when compared with independent forest inventory and analysis (FIA) data from USDA Forest Service.50 The conifer-hardwood forest covered a much larger area in the FFC map than in NLCD 2006 data either inside or outside ISF and is much more detailed than the forest cover classifications in NLCD 2006 [Fig. 5(c)]. 5.DiscussionThis study is the first demonstration of the DUC algorithm30 for a real-world classification exercise with an integration of remotely sensed and plot-based forest data. Lang et al.30 designed and tested the DUC algorithm to classify several sample sites into four general land covers, including agriculture, forest, urban, and water. In this study, we applied this algorithm to a much larger site, the ISF with the 8-km surrounding areas. We focused on and split the forests into more detailed forest types, which was more difficult than the general land cover classification due to the similarities. The classification accuracy of such an unsupervised classification approach is determined mainly by imagery quality and sample data. The two-season Landsat TM datasets we used in this study provide richer spectral information than single-season imagery for the classifications of hardwood forests. The CFI plots used in this study were abundant though their distribution among forest types was uneven. All these factors contributed to the development of the FFC map that is reasonably consistent with field survey data. This shows that the integration of image data and forest field data has made the resultant forest cover map more realistic and objective than the use of image data alone. The overall accuracy of the forest cover map derived at the second stage was unexpectedly greater than that at the first stage. The reason for this phenomenon may be that spectral classes derived from a larger forest area (ISF and the 8-km surrounding areas) have better representations to forest types than those from a smaller forest area (ISF). Because most sample points are located inside ISF, forest cover information within ISF may be more reliable than that outside ISF. The producer’s accuracy of maple forest type in the second stage was lower than that in the first stage; however, the user’s accuracy had significant increases. This means the FFC map created in the first stage overestimated the maple. The FFC of the second stage showed a lower quantity disagreement. It is also reasonable for the additional misclassified maple plots dropping into oak-hickory forest type because maples are shade tolerance species and are usually suppressed under the oak-hickory forests. The same trend of accuracies happened in mixed hardwood forest, where the producer’s accuracy decreased and the user’s accuracy increased. However, there was no confidential evidence to show that mixed hardwood was overestimated in the first stage. FFC in the second stage might have underestimated the mixed hardwood because the total number of mixed hardwood samples in the resultant map was much smaller than that in the reference data. The decrease of the allocation disagreement showed that FFC in the second stage would likely have a better quality. The classification accuracy is also affected, in theory, by spatial mismatch between pixel coordinates and plot locations. The coordinates of the CFI plots used in this study were measured with handheld global positioning system (GPS) receivers and their errors are normally up to 10 m.51 The combination of the GPS error and TM image geometric error can be problematic for heterogeneous forest canopies. The coverage of this type of forest inventory data is available for limited forest areas, geographically restricting the applications of the data-assisted unsupervised classifications. Given the first experiment with the classification method, we suggest that it should be broadly applied with the following considerations:
An important feature of the DUC algorithm is its repeatability, meaning that the classification procedure can be systematically modified by simply changing classification parameters and labeling rules if classification results are not satisfactory, thus the loops in the flow chart of the two-stage unsupervised classification (Fig. 2). Our experience indicates that an automated computer program for recoding can make the classification less labor intensive and reduce human errors in labeling processes despite hundreds of spectral classes. Analysts only need to have fundamental remote sensing training to implement this classification technique. Forest inventory data, such as FIA, have been used in various ways to improve forest assessment together with remotely sensed imagery.40,53,54 If researchers can access the exact FIA plot locations, the FIA-DUC approach can be broadly applied at the regional and national scales in the United States. Such a forest mapping procedure will help save time and money due to a reduction in the necessary ground validation. 6.ConclusionsThis study demonstrates the first application of the DUC algorithm in dividing hardwood forests into three forest types in an objective fashion. The overall quality of the resultant forest cover map suggests that the DUC approach with forest inventory data is an effective and efficient method for mapping forest cover in Indiana. However, current ground data do not allow us to classify the hardwood forest into even more detailed levels with satisfactory accuracy. A stepwise classification procedure of species composition overcomes the difficulties caused by the extremely uneven distribution of ground data. The two-stage DUC algorithm successfully extends the mapping area to 8 km away from the plot-based forest data without jeopardizing classification accuracy. This forest mapping technique is suitable for mapping other forest areas where extensive plot data are available. A forest cover map needs to be noise free if it is to be used for forest management activities in the field. In other words, the minimum mapping unit will likely be greater than pixel size of the remote sensing imagery at a proper scale based on the objective of the map to reduce salt-and-pepper or noise pixels. A forest cover map derived from pixel-based classifications can be filtered to remove noise pixels by using image processing algorithms, such as connected component analysis and morphology fundamentals processing. It is also possible to integrate spectral classes with image segmentation to obtain patch-style spectral classes, based on which labeling procedure is implemented. Such comprehensive experiments need systematic explorations in the future. ReferencesS. E. FranklinM. A. Wulder,
“Remote sensing methods in medium spatial resolution satellite data land cover classification of large areas,”
Prog. Phys. Geogr., 26
(2), 173
–205
(2002). http://dx.doi.org/10.1191/0309133302pp332ra PPGEEC 0309-1333 Google Scholar
S. D. JawakA. J. Luis,
“Improved land cover mapping using high resolution multiangle 8-band worldview-2 satellite remote sensing data,”
J. Appl. Remote Sens., 7
(1), 073573
(2013). http://dx.doi.org/10.1117/1.JRS.7.073573 1931-3195 Google Scholar
W. B. Cohenet al.,
“Modelling forest cover attributes as continuous variables in a regional context with Thematic Mapper data,”
Int. J. Remote Sens., 22
(12), 2279
–2310
(2001). http://dx.doi.org/10.1080/01431160121472 IJSEDK 0143-1161 Google Scholar
J. L. OhmannM. J. Gregory,
“Predictive mapping of forest composition and structure with direct gradient analysis and nearest-neighbor imputation in coastal Oregon, USA,”
Can. J. For. Res., 32
(4), 725
–741
(2002). http://dx.doi.org/10.1139/x02-011 CJFRAR 0045-5067 Google Scholar
K. M. Bergenet al.,
“Remote sensing of vegetation 3‐D structure for biodiversity and habitat: review and implications for lidar and radar spaceborne missions,”
J. Geophys. Res.: Biogeosci., 114
(G2), 2005
–2012
(2009). http://dx.doi.org/10.1029/2008jg000883 Google Scholar
E. H. Helmeret al.,
“Detailed maps of tropical forest types are within reach: forest tree communities for Trinidad and Tobago mapped with multiseason Landsat and multiseason fine-resolution imagery,”
For. Ecol. Manage., 279
(1), 147
–166
(2012). http://dx.doi.org/10.1016/j.foreco.2012.05.016 FECMDW 0378-1127 Google Scholar
J. A. Fryet al.,
“Completion of the 2006 National Land Cover Database for the Conterminous United States,”
Photogramm. Eng. Remote Sens., 77
(9), 859
–864
(2011). PGMEA9 0099-1112 Google Scholar
J. R. Anderson E. E. HardyJ. T. Roach,
“A land use and land cover classification system for use with remote sensor data,”
(1976). Google Scholar
D. R. Breiningeret al.,
“Landcover characterizations and Florida scrub-jay (Aphelocomacoerulescens) population dynamics,”
Biol. Conserv., 128
(2), 169
–181
(2006). http://dx.doi.org/10.1016/j.biocon.2005.09.026 BICOBK 0006-3207 Google Scholar
Indiana Department of Natural Resources, Division of Forestry, “Increased emphasis on management and sustainability of oak-hickory communities on the Indiana State forest system, 2008–2027,”
(2008) http://www.in.gov/dnr/forestry/files/fo-StateForests_EA.pdf Google Scholar
R. K. Swihartet al.,
“The hardwood ecosystem experiment: a framework for studying responses to forest management,”
(2013). http://www.nrs.fs.fed.us/pubs/42882 Google Scholar
G. M. Foody,
“Status of land cover classification accuracy assessment,”
Remote Sens. Environ., 80
(1), 185
–201
(2002). http://dx.doi.org/10.1016/S0034-4257(01)00295-4 RSEEA7 0034-4257 Google Scholar
G. F. ShaoJ. G. Wu,
“On the accuracy of landscape pattern analysis using remote sensing data,”
Landsc. Ecol., 23
(1), 505
–511
(2008). http://dx.doi.org/10.1007/s10980-008-9215-x LAECEH 0921-2973 Google Scholar
S. Adelabuet al.,
“Exploiting machine learning algorithms for tree species classification in a semiarid woodland using RapidEye image,”
J. Appl. Remote Sens., 7
(1), 073480
(2013). http://dx.doi.org/10.1117/1.JRS.7.073480 1931-3195 Google Scholar
J. Gallion,
“Indiana’s forest resource in 2011,”
(2011) http://www.inwoodlands.org/indianas_forest_resource_in_20/ Google Scholar
J. GallionC. Woodall,
“The sustainability of Indiana’s forest resources,”
(2010) http://www.in.gov/dnr/forestry/files/fo-SIFR(lowres).pdf Google Scholar
R. Pu,
“Broadleaf species recognition with in situ hyperspectral data,”
Int. J. Remote Sens., 30
(11), 2759
–2779
(2009). http://dx.doi.org/10.1080/01431160802555820 IJSEDK 0143-1161 Google Scholar
W. E. Thogmartinet al.,
“Population-level impact of white-nose syndrome on the endangered Indiana bat,”
J. Mammal., 93
(4), 1086
–1098
(2012). http://dx.doi.org/10.1644/11-MAMM-A-355.1 JOMAAL 0022-2372 Google Scholar
Myotis sodalis, The IUCN red list of threatened species, http://www.iucnredlist.org/details/14136/0 Google Scholar
R. L. Clawson,
“Trends in population size and current status,”
The Indiana Bat: Biology and Management of an Endangered Species, 2
–8 Bat Conservation International, Austin, TX
(2002). Google Scholar
W. E. Thogmartinet al.,
“White-nose syndrome is likely to extirpate the endangered Indiana bat over large parts of its range,”
Biol. Conserv., 160
(April), 162
–172
(2013). http://dx.doi.org/10.1016/j.biocon.2013.01.010 BICOBK 0006-3207 Google Scholar
E. V. CallahanR. D. DrobneyR. L. Clawson,
“Selection of summer roosting sites by Indiana bat (Myotissodalis) in Missouri,”
J. Mammal., 78
(3), 818
–825
(1997). http://dx.doi.org/10.2307/1382939 JOMAAL 0022-2372 Google Scholar
B. P. Pauli,
“Nocturnal and diurnal habitat of Indiana and Northern long-eared bats, and the simulated effect of timber harvest on habitat suitability,”
Purdue University, West Lafayette, Indiana,
(2014). Google Scholar
Gap Analysis Bulletin No. 16, March 2009, http://www.gap.uidaho.edu/bulletins/16/Indiana.pdf Google Scholar
J. R. Jensen, Introductory Digital Image Processing: A Remote Sensing Perspective, 3rd ed.Prentice Hall, NY
(2005). Google Scholar
Y. TarabalkaJ. A. BenediktssonJ. Chanussot,
“Spectral-spatial classification of hyperspectral imagery based on partitional clustering techniques,”
IEEE Trans. Geosci. Remote Sens., 47
(8), 2973
–2987
(2009). http://dx.doi.org/10.1109/TGRS.2009.2016214 IGRSD2 0196-2892 Google Scholar
G. MountrakisJ. ImC. Ogole,
“Support vector machines in remote sensing: a review,”
ISPRS J. Photogramm. Remote Sens., 66
(3), 247
–259
(2011). http://dx.doi.org/10.1016/j.isprsjprs.2010.11.001 IRSEE9 0924-2716 Google Scholar
D. S. LuQ. H. Weng,
“A survey of image classification methods and techniques for improving classification performance,”
Int. J. Remote Sens., 28
(5), 823
–870
(2007). http://dx.doi.org/10.1080/01431160600746456 IJSEDK 0143-1161 Google Scholar
R. L. Langet al.,
“Optimizing unsupervised classifications of remotely sensed imagery with a data-aided labeling approach,”
Comput. Geosci., 34
(12), 1877
–1885
(2008). http://dx.doi.org/10.1016/j.cageo.2007.10.011 CGEODT 0098-3004 Google Scholar
J. Franklinet al.,
“Rationale and conceptual framework for classification approaches to assess forest resources and properties,”
Remote Sensing of Forest Environments, 279
–300 2003). Google Scholar
M. SongD. L. CivcoJ. D. Hurd,
“A competitive pixel-object approach for land cover classification,”
Int. J. Remote Sens., 26
(22), 4981
–4997
(2005). http://dx.doi.org/10.1080/01431160500213912 IJSEDK 0143-1161 Google Scholar
B. Schmooket al.,
“A step-wise land-cover classification of the tropical forests of the Southern Yucatán, Mexico,”
Int. J. Remote Sens., 32
(4), 1139
–1164
(2011). http://dx.doi.org/10.1080/01431160903527413 IJSEDK 0143-1161 Google Scholar
S. W. MurrayA. Kurta,
“Nocturnal activity of the endangered Indiana bat (Myotissodalis),”
J. Zool., 262
(2), 197
–206
(2004). http://dx.doi.org/10.1017/S0952836903004503 JZOOAE 0952-8369 Google Scholar
D. W. Sparkset al.,
“Foraging habitat of the Indiana bat (Myotissodalis) at an urban–rural interface,”
J. Mammal., 86
(4), 713
–718
(2005). http://dx.doi.org/10.1644/1545-1542(2005)086[0713:FHOTIB]2.0.CO;2 JOMAAL 0022-2372 Google Scholar
R. A. Hillet al.,
“Mapping tree species in temperate deciduous woodland using time-series multi-spectral data,”
Appl. Veg. Sci., 13
(1), 86
–99
(2010). http://dx.doi.org/10.1111/avsc.2010.13.issue-1 1402-2001 Google Scholar
J. Gallion,
“Report of Continuous Forest Inventory (CFI)—Summary of year 1–5 (2008–2012),”
http://www.in.gov/dnr/forestry/files/fo-CFI_Report_2008-12.pdf Google Scholar
R. G. Congalton,
“A review of assessing the accuracy of classifications of remotely sensed data,”
Remote Sens. Environ., 37
(1), 35
–46
(1991). http://dx.doi.org/10.1016/0034-4257(91)90048-B RSEEA7 0034-4257 Google Scholar
L. LeefersN. Subedi,
“Forest type classification accuracy assessment for Michigan’s State and National Forests,”
North. J. Appl. For., 29
(1), 35
–42
(2012). http://dx.doi.org/10.5849/njaf.09-024 NJAFEN Google Scholar
D. S. Luet al.,
“Relationships between forest stand parameters and Landsat TM spectral responses in the Brazilian Amazon Basin,”
For. Ecol. Manage., 198
(1), 149
–167
(2004). http://dx.doi.org/10.1016/j.foreco.2004.03.048 FECMDW 0378-1127 Google Scholar
G. F. Shaoet al.,
“Forest cover types derived from Landsat Thematic Mapper imagery for Changbai Mountain area of China,”
Can. J. For. Res., 26
(2), 206
–216
(1996). http://dx.doi.org/10.1139/x26-024 CJFRAR 0045-5067 Google Scholar
FAQ about the Landsat Missions, http://landsat.usgs.gov/best_spectral_bands_to_use.php Google Scholar
P. S. Johnsonet al., The Ecology and Silviculture of Oaks,
(2009). Google Scholar
R. G. PontiusM. Millones,
“Death to kappa: birth of quantity disagreement and allocation disagreement for accuracy assessment,”
Int. J. Remote Sens., 32
(15), 4407
–4429
(2011). http://dx.doi.org/10.1080/01431161.2011.552923 IJSEDK 0143-1161 Google Scholar
Q. McNemar,
“Note on the sampling error of the difference between correlated proportions or percentages,”
Psychometrika, 12
(2), 153
–157
(1947). http://dx.doi.org/10.1007/BF02295996 0033-3123 Google Scholar
A. H. Bowker,
“A test for symmetry in contingency tables,”
J. Am. Stat. Assoc., 43
(244), 572
–574
(1948). http://dx.doi.org/10.1080/01621459.1948.10483284 JSTNAL 0003-1291 Google Scholar
J. D. Wickhamet al.,
“Accuracy assessment of NLCD 2006 land cover and impervious surface,”
Remote Sens. Environ., 130
(15), 294
–304
(2013). http://dx.doi.org/10.1016/j.rse.2012.12.001 RSEEA7 0034-4257 Google Scholar
What types of tree grow in Indiana, http://na.fs.fed.us/spfo/pubs/misc/in98forests/webversion/whatypes.htm Google Scholar
M. G. WingA. EklundL. D. Kellogg,
“Consumer-grade global positioning system (GPS) accuracy and reliability,”
J. For., 103
(4), 169
–173
(2005). http://dx.doi.org/10.5849/sjaf.13-006 Google Scholar
G. F. Shaoet al.,
“An explicit index for assessing the accuracy of cover class areas,”
Photogramm. Eng. Remote Sens., 69
(8), 907
–913
(2003). http://dx.doi.org/10.14358/PERS.69.8.907 PGMEA9 0099-1112 Google Scholar
M. D. Nelsonet al.,
“Combining satellite imagery with forest inventory data to assess damage severity following a major blow down event in northern Minnesota, USA,”
Int. J. Remote Sens., 30
(19), 5089
–5108
(2009). http://dx.doi.org/10.1080/01431160903022951 IJSEDK 0143-1161 Google Scholar
Y. Zhanget al.,
“Integration of satellite imagery and forest inventory in mapping dominant and associated species at a regional scale,”
Environ. Manage., 44
(2), 312
–323
(2009). http://dx.doi.org/10.1007/s00267-009-9307-7 EMNGDC 1432-1009 Google Scholar
BiographyGang Shao received his BS in biomedical information engineering from Northeastern University in China and his MS in forestry and natural resources from Purdue University, USA. He is currently a PhD student in forestry and natural resources at Purdue University, USA. Benjamin P. Pauli received his BA in biology from Lawrence University, USA, and received his MS and PhD in quantitative ecology from Purdue University, USA. He is currently a postdoctoral researcher at Boise State University, USA. G. Scott Haulton received a BS in English from the State University of New York College at Geneseo, USA, a BS in environmental and forest biology from the State University of New York College of Environmental Science and Forestry, USA, and an MS in wildlife science from Virginia Tech, USA. He is current a forestry wildlife specialist with the Indiana Department of Natural Resources, Division of Forestry. Patrick A. Zollner received his BS in natural resources from University of Michigan, USA, his MS in wildlife ecology from Mississippi State University, USA, and his PhD in ecology from Indiana State University, USA. He is currently an associate professor of quantitative ecology in the Department of Forestry and Natural Resources, Purdue University, USA. Guofan Shao received the PhD degree in ecology from the Chinese Academy of Sciences, Shenyang, China, and received postdoctoral education from the Department of Environmental Sciences, University of Virginia, USA. He is currently a professor with the Department of Forestry and Natural Resources, Purdue University, USA. His main research interests focus on remote-sensing data analysis and error propagation, landscape quantification, urbanization processes, and geospatial modeling. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||





